

مدیریت حافظه در Go
مقدمه
معمولاً وقتی درباره حافظه صحبت میکنیم، ذهنمان به سمت اصطلاحاتی مانند stack overflow ،memory leak و garbage collector میرود. وجه مشترک تمام این اصطلاحات، حافظه یک برنامه در زمان اجرا است. در این مقاله یک تصویر شفاف از حافظه برنامهها میسازیم و سپس، رویکرد زبان Go را در مدیریت دو بخش اصلی حافظه، یعنی Stack و Heap، بررسی خواهیم کرد. همچنین، به مرور مفاهیم Escape Analysis ،Growing/Shrinking Stack و الگوریتم Mark & Sweep خواهیم پرداخت.
چرا حافظه مهمه؟ (تجربه ما)
یک نرمافزار مدیریت منابع سازمانی (یا همان ERP) Cloud Native را تصور کنید. طبق تجربه همکاران سیستم، زیرساخت ابری این نرمافزار بیش از ۱۰ هزار مشتری (شرکت) خواهد داشت. هر شرکت در اوج فعالیت به صورت میانگین ۱۰۰ درخواست در ثانیه دارد (100 RPS). متناظر با هر درخواست، یک thread جدید ایجاد میشود. فرض کنید که هر thread، فقط به میزان 1MB حافظه بیشتری از چیزی که نیاز دارد بگیرد. در این حالت، 1TB حافظه RAM بیشتری مورد نیاز خواهد بود. این عدد برای RAM بسیار بالاست! تصور کنید که scale شدن این نرمافزار فقط به دلیل RAM چقدر دشوار تر خواهد بود؟
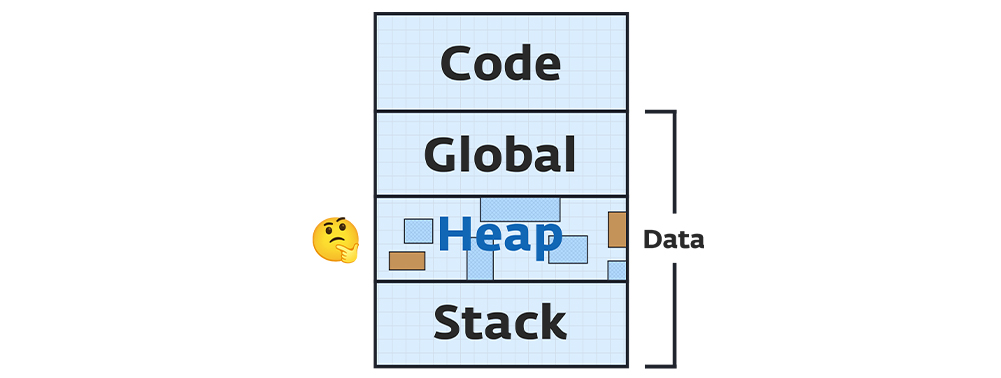
۱) تصویر کلی از حافظه یک برنامه
به صورت کلی، حافظهی یک برنامه به دو بخش اصلی تقسیم میشود:
۱. Code Segment: شامل کد برنامه و دستوراتی که CPU اجرا میکند.
۲. Data Segment: شامل دادههای یک برنامه را در زمان اجرا.
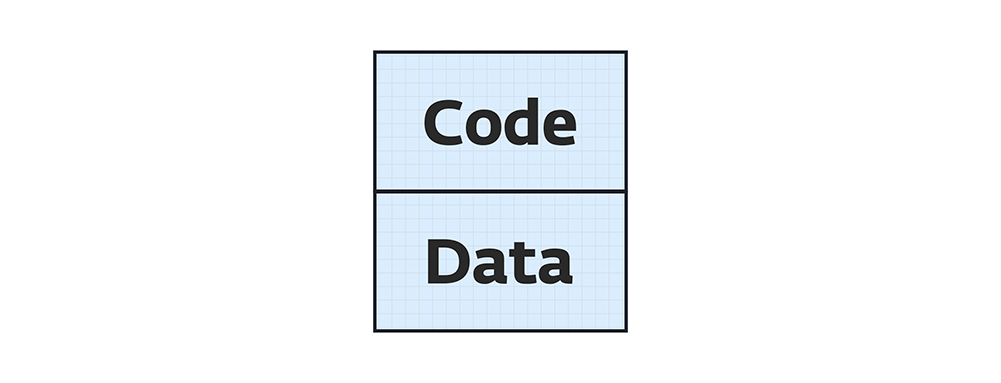
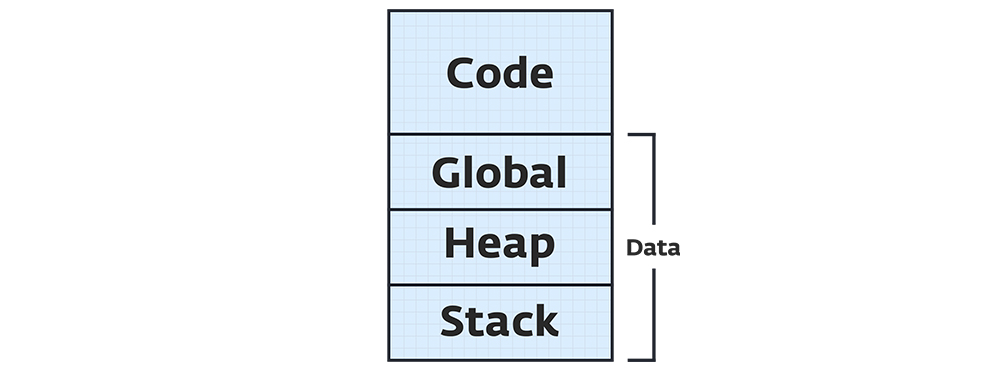
Data segment برنامه از این سه بخش تشکیل میشود:
۱. Global: محل نگهداری متغیرهای سراسری که اندازه آنها در زمان کامپایل مشخص است.
۲. Stack: محل نگهداری متغیرهای محدود به توابع.
۳. Heap: محل نگهداری متغیرهای بزرگتر و با طول عمر فراتر از محدوده توابع.
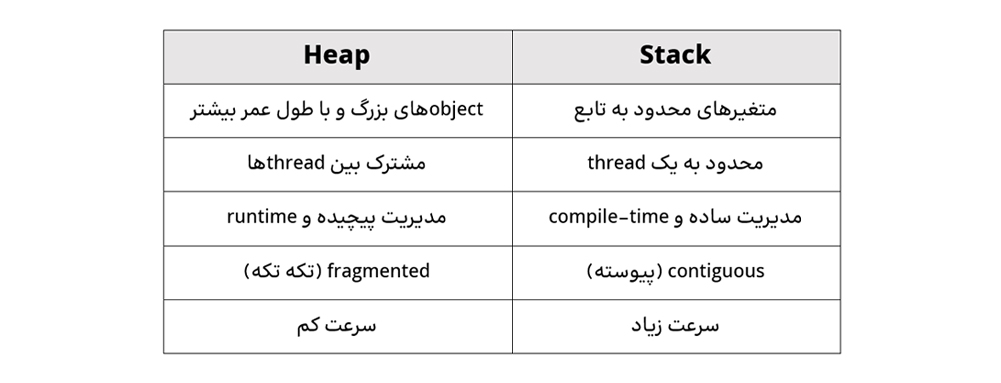
۲) تفاوتهای Stack و Heap
تفاوتهای این دو حافظه را میتوان در جدول زیر خلاصه کرد:
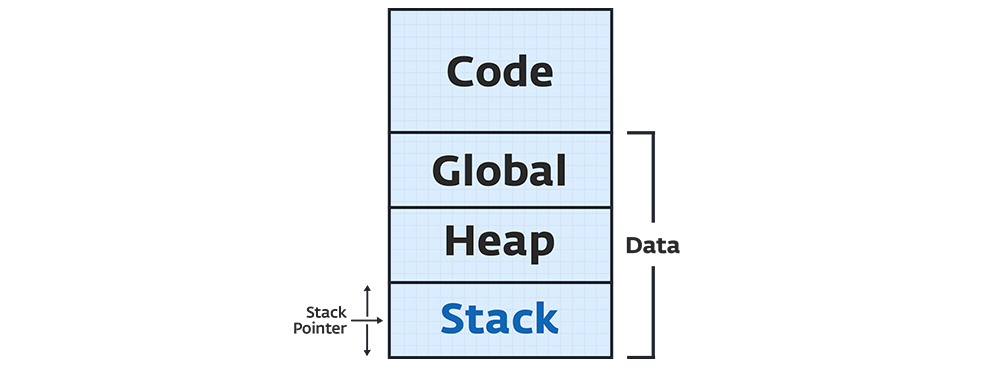
چرا Stack سریعتر است؟
حافظه Stack از یک فضای پیوسته + یک اشارهگر (Stack pointer) تشکیل میشود. به عبارتی، قبل از Stack pointer حافظه کاملاً allocated و بعد از آن کاملاً آزاد است. با فراخوانی یک تابع مانند sum ،stack pointer به اندازه متغیرهای تابع افزایش مییابد. یعنی جمع حافظه متغیرهای a ،b و result به stack pointer اضافه میشود. پس از پایان کار تابع، به همان اندازه stack pointer کاهش مییابد. سازوکار تخصیص (allocation) و آزادسازی (deallocation) در stack، با همین عملیات جمع و تفریق ساده تعریف میشود. به همین دلیل، مدیریت حافظه stack به صورت سریع و خودکار قابل انجام است.
func sum(a, b int) int {
result := a + b
return result
}چرا به Heap نیاز داریم؟
با وجود مزیتهایی که بیان کردیم، حافظه Stack محدود است. تا زمانی که متغیرها در چارچوب توابع استفاده شوند، نگهداری و مدیریت آنها در Stack امکانپذیر است. اما در برخی شرایط، دیگر حافظه مورد نیاز در زمان کامپایل قابل تعیین نیست یا این که طول عمر متغیرها نمیتواند محدود به توابع باشد. به عنوان مثال:
طول slice، یک ورودی از شبکه باشد.
حجم object آنقدر بزرگ باشد که کپی آن بین توابع هزینهبر باشد.
نیاز داشته باشیم یک object بین چند goroutine به اشتراک گذاشته شود.
در این شرایط دیگر ساختار local و محدود stack پاسخگو نیست. به خاطر این موضوعات، حافظه heap نیز برای برنامهها طراحی شده است. این حافظه، آزادی عمل بیشتری را فراهم میکند؛ در عین حال، چالشهای خود را نیز به همراه دارد:
۱. پیچیدگی Allocation: باید در یک فضای بزرگ، یک بخش پیوسته را برای object جستوجو کرد.
۲. پیچیدگی Deallocation: طول عمر متغیرها از محدودهی توابع خارج شده است. آزادسازی حافظه تخصیص داده شده باید در زمان درست توسط برنامهنویس یا garbage collector به صورت دستی انجام شود.
۳. Fragmentation: رویکرد allocation و deallocation در heap، باعث تکه تکه شدن این حافظه میشود.
۴. Synchronization: حافظهی مشترک، چالش race condition و synchronization را دوچندان میکند.
۵. سرعت کمتر: در نتیجهی تمام این موارد، heap حافظه کندتری نسبت به stack است.
۳) مدیریت Stack در Go
زبان Go از دو جنبه نگاه متفاوتی به حافظه stack داشته است:
۱. متغیرها تا حد امکان روی stack قرار گیرند.
۲. اندازهی stack ثابت نباشد.
فلسفه Stack First
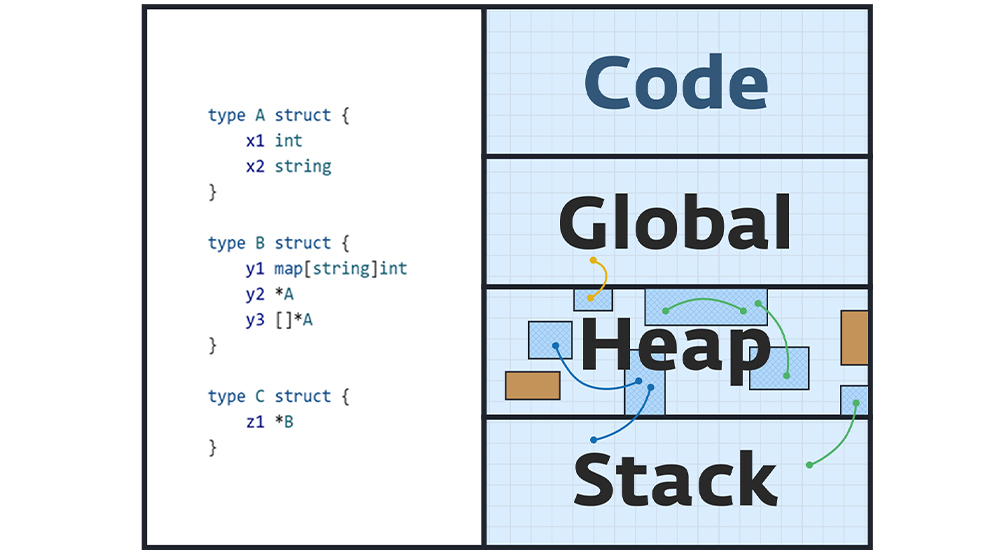
در Go یک فلسفهی مهم وجود دارد؛ متغیرها تا حد امکان روی stack قرار گیرند. نکتهی کلیدی آن است که برنامهنویس مستقیماً تصمیم نمیگیرد که یک متغیر در stack قرار گیرد یا heap. بلکه این تصمیم با Escape Analyzer در کامپایلر است. بنابراین، استفاده از کلیدواژهی new یا تعریف متغیرهای primitive، روی محل allocation تاثیری ندارد.
کامپایلر Go بررسی میکند که آیا یک متغیر از محدودهی تابع فرار میکند یا نه. اگر متغیر درون تابع باقی بماند، معمولاً در حافظهی stack نگهداری میشود. در غیر این صورت، روی حافظهی heap نگهداری خواهد شد.
func foo() int {
x := 10 // variable does not escape
return x
}
func bar() *int {
x := 10 // pointer escapes function scope
return &x
}با استفاده از دستور زیر میتوان خروجی escape analyzer و تصمیمگیری برای محل نگهداری هر متغیر را مشاهده کرد:
go build -gcflags=”-m” main.goبه عنوان مثال میتوان خروجی آن را برای کد زیر مشاهده کرد:
package main
import "fmt"
func main() {
}
func foo() {
x := "hello"
go func() {
fmt.Println(x)
} ()
}
درباره Growing / Shrinking Stack
بر خلاف زبانهایی مانند C که در آنها stack هر thread از ابتدا با اندازهی ثابتی در نظر گرفته میشود، در Go هر goroutine کار خود را با stack کوچکی با حجم 2KB شروع میکند. اگر stack پر شود:
۱. یک stack جدید با اندازهی دو برابر ساخته میشود.
۲. محتوای stack قبل در آن کپی میشود.
۳. stack قبل آزاد میشود.
این رشد (grow) میتواند تا حتی 1GB نیز ادامه پیدا کند. به صورت مشابه، حافظه stack میتواند کاهش یابد (shrink). دو دلیل اصلی برای این طراحی وجود دارد:
۱. escape analyzer در اولویت دادن به stack، کمتر درگیر محدودیت اندازه شود.
۲. goroutineها سبک باقی بمانند و در scale میلیونها goroutine، به خاطر حجم اولیه stack چالش کمتری داشته باشیم.
۴) مدیریت Heap در Go
شاید بتوان چالش اصلی در رابطه با heap را deallocation نام برد. در زبانهای مانند C، آزادسازی heap به صورت دستی انجام میشود که مشکلاتی مانند dangling pointer و double free را به همراه دارد. در Go، این مسئولیت با Garbage Collector (GC) است.
زبان Go کامپایلری است و در نتیجهی کامپایل آن، یک فایل executable و مستقل تولید میشود. برای یک کد بسیار ساده، خروجی کامپایل شده حدود 2MB حجم دارد. بخش قابل توجهی از فایل خروجی، به runtime اختصاص دارد. runtime مسئولیتهای مهمی اعم از مدیریت goroutine scheduler، stackها، panicها، system callها و البته، GC زبان Go را به عهده دارد. زمان اجرای یک برنامهی Go، runtime یک thread جدا برای GC ایجاد میکند.

GC در طول عمر برنامه به صورت چرخهای (cycle) اجرا میشود. یکی از تخمینهای اصلی برای شروع چرخهی بعد، میزان رشد حافظهی heap نسبت به چرخهی قبل است. مثلاً اگر حجم heap در چرخهی قبل 2MB بوده باشد و اکنون تا 4MB رشد کرده باشد (100% افزایش)، runtime چرخهی بعد GC را آغاز میکند. این رفتار با استفاده از متغیر محیطی GOGC قابل تنظیم است:
GOGC=off # no garbage collection
GOGC=200 # collect less aggressively
GOGC=100 # default
GOGC=50 # collect more aggressively
الگوریتم Mark & Sweep
به شکل ساده، اگر حافظهای دیگر در دسترس نباشد، زباله (garbage) شناخته میشود. مثلاً اگر از طریق stack فعلی برنامه دیگر نتوان مسیری برای دسترسی به یک object در heap پیدا کرد، آن حافظه، unreachable است. تشخیص یک بخش از حافظه به عنوان garbage ساده نیست. چون حافظهها در heap یک ساختار گراف تشکیل میدهند. اگر یک ریشه در این گراف از دسترس خارج شود، تمام حافظههایی که فقط از آن طریق در دسترس بودند نیز unreachable خواهند شد و باید آزاد شوند.
در Go، شناسایی و آزادسازی garbageها در حافظه با استفاده از الگوریتم Mark & Sweep صورت میگیرد. این الگوریتم از سه مرحلهی اصلی تشکیل میشود:
۱. Stop The World (STW): برای لحظهای کوتاه، اجرای تمام goroutineهای برنامه متوقف میشود تا نقاط شروع (ریشهها) برای جستوجو مشخص شوند. نقاط شروع از متغیرهای global و stackهای فعال تشکیل میشوند.
۲. Mark: پیمایش گراف از ریشهها شروع شده و هر آن چه که reachable باشد علامتگذاری (mark) میشود. این مرحله با همزمانی بالا و حتی به صورت parallel روی هستههای مختلف CPU قابل اجراست.
۳. Sweep: حافظههایی که mark نشده باشند، unreachable هستند و به عنوان garbage، جارو (sweep) میشوند. این مرحله نیز با همزمانی بالایی مشابه مرحلهی mark قابل اجراست.
باید توجه داشت که GC زبان Go از نوع non-moving است. حافظه heap ذاتاً fragmentation دارد و یکی از راههای بهبود این موضوع، جا به جا کردن objectها یا به عبارتی، defrag کردن حافظه است. در Go این کار انجام نمیشود. مزایای این تصمیم، performance بهتر و ثابت بودن اشارهگرهای زبان است. یعنی میتوان از اشارهگرها به عنوان identity متغیرها استفاده کرد.
جمعبندی
در این مقاله، ابتدا به بیان تفاوتهای ذاتی بین دو حافظهی stack و heap پرداختیم. این که stack سریع، پیوسته، ساده اما محدود است. در حالی که heap انعطاف بیشتری دارد اما کندتر و پیچیدهتر است. با در نظر گرفتن این تمایزها، رویکرد زبان Go در مدیریت این دو حافظه را بیان کردیم. به دلیل مزیتهای stack، Go با استفاده از escape analysis در زمان کامپایل تلاش میکند تا متغیرها تا حد امکان روی stack نگهداری شوند. همچنین، حافظهی stack میتواند اندازهی متغیری داشته باشد (growing/shrinking). در نهایت، بیان کردیم که حافظهی heap توسط GC و در چرخههای مشخصی با الگوریتم Mark & Sweep مدیریت شده و این الگوریتم در حال حاضر به صورت non-moving عمل میکند.
مزایا و معایبی را مطرح کردیم که پارامترهای انتخاب زبان backend را برای یک پروژه تشکیل میدهند. به عنوان مثال، این که سرعت حافظه اولویت داشته باشد و از این رو، بیشتر stack انتخاب شود. یا این که هر go routine، کار خودش را با یک stack بسیار کوچک شروع کند اما اندازهی آن قابل تغییر باشد تا این موضوع در یک نرمافزار cloud native، که در هر ثانیه تعداد بسیار بالایی درخواست دارد، go routine متناظر با درخواست منابع کنترل شدهای را مصرف کند و scale شدن نرمافزار، مثل ERP نسل جدید همکاران سیستم، امکانپذیر شود.
اگر دوست دارید بحث مدیریت حافظه در Go را عمیقتر دنبال کنید، ویدئوی کامل ارائه من در رویداد «تکوتاک ۰۲» از طریق این لینک قابل مشاهده است.
چگونه در اینستاگرام بتونیم در Bio چندین لینک بزاریم ؟
افرادی که باز میگردند.
روایتهایی از تجربه، یادگیری و رشد در تیم تولید همکاران سیستم