

سفر در زمان برای نجات دادهها!
"داستان تجربه ما از پیادهسازی پشتیبانگیری پیوسته پایگاه داده در محیط ابری"
تهیه پشتیبان به صورت پیوسته و قابلیت بازگشت به اونها در زمانهای بحران، یکی از مهمترین خصیصههای یک نرمافزار سازمانی مطمئنه. در این مقاله با هم به بررسی یکی از چند روش پیادهسازی شده برای تهیه پشتیبان از پایگاههای داده مشتریان سرویسهای ابری همکاران سیستم که حداکثر میزان از بین رفتن داده رو به ۱۰ دقیقه میرسونه میپردازیم.

با طراحی و قطعی شدن معماری نسل جدید محصولات همکاران سیستم، یکی از مهمترین چالشهایی که در تیم DevOps با اون مواجه بودیم، طراحی روشی برای پشتیبانگیری و نگهداری پیوسته دادههای مشتریها بود. یکی از اصولی که ما برای خودمون تعریف کردیم ارزش داده مشتری بود و طبق این اصل باید همیشه و در هر زمانی داده مشتری رو به عنوان اولویت اول خودمون در نظر میگرفتیم. تجربه چندین ساله شرکت به ما میگفت که قراره با چندین هزار مشتری - که با توجه به الگوهای استفادهشون از محصول، در دستههای متنوعی قرار میگیرن - مواجه خواهیم شد. برای همین به عنوان اولین قدم تصمیم گرفتیم که پیشفرضهایی داشته باشیم تا در ادامه راه بتونیم بر اساس اونها مطمئنتر تصمیم بگیریم.
نسل جدید محصولات ما بر اساس اصول Cloud Native طراحی شده بودن و قرار بود که بر روی یک زیرساخت بر پایه کوبرنیتیز مستقر بشن. به همین خاطر اولین فرضیه ما که از فرض همگونی محصولات ابری نشأت میگرفت این بود که باید میزان کارهای دستی که در مسیر پشتیبانگیری و بازگردانی انجام میشن رو به حداقل برسونیم تا با افزایش تعداد مشتریها دچار آفتهای کار دستی مثل خطاهای انسانی و اتلاف وقت و کندی نشیم.
فرض دوم ما از نیازمندیهای کسبوکاری ما میاومد، قرار بود که مشتریهای ما از نظر تعداد زیاد و همینطور در طیف گستردهای باشن. این طیف گسترده در دو نقطه با چالش فعلی ما مرتبط بود. نقطه اول حجم دادهها بود، بر اساس تجربههای گذشته میدونستیم که قراره با مشتریهایی با حجم داده چند ده گیگابایت تا چند ترابایت مواجه باشیم. نقطه دوم هم میزان کارکرد مشتری با سیستم و تعداد تراکنشهایی که در واحد زمان با سیستم داشتن بود. با توجه به این نیازمندیها، راهحل ما باید یک حداقلی از سنجههای RPO و RTO که در ادامه به معنی اونها خواهیم پرداخت رو برای همه مشتریها، فارغ از حجم داده و نرخ تراکنشهای اونها فراهم میکرد.
سومین فرض ما این بود که به هیچ روشی اعتماد کامل نداشته باشیم! برای همین تصمیم گرفتیم که حداقل در شروع مسیر با چندین روش مختلف از دادهها پشتیبان بگیریم تا اگر یک روش خاص در ادامه با مشکل مواجه شد نگرانیای بابت از دست رفتن دادههای مشتری نداشته باشیم و در ادامه به صورت دورهای از سلامت دادههای پشتیبان اطمینان حاصل کنیم.
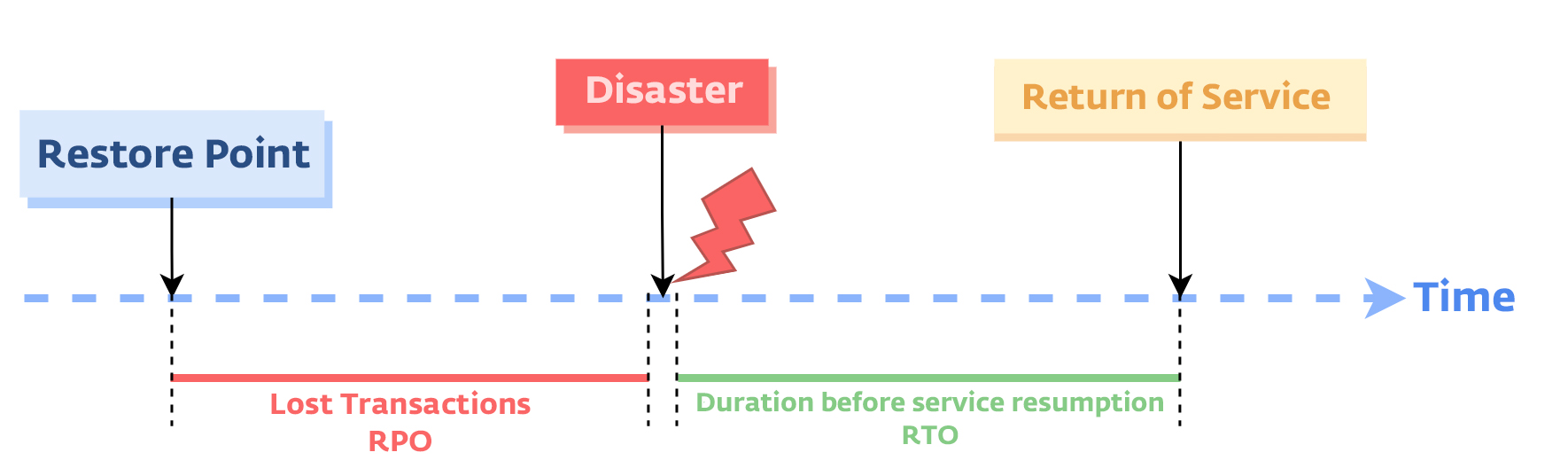
با مشخص شدن پیشفرضهایی که در طراحی راهحل به دنبال اونها بودیم، تصمیم به هدفگذاری با دو سنجه مهم RPO و RTO گرفتیم. سنجه RPO یا Recovery Point Objective مشخص میکنه که در صورت اتفاق افتادن یک حادثه که نیاز به بازگردانی داده رو ایجاد میکنه، حداکثر میزان از دست دادن دادهها چند دقیقه خواهد بود و در ادامه سنجه RTO یا Recovery Time Objective مشخص میکنه که در صورت اتفاق افتادن یک حادثه که نیاز به بازگردانی داده رو ایجاد میکنه، حداکثر میزان زمان مورد نیاز برای بازگردانی دادهها چقدر خواهد بود. ما با توجه به ساختار و مدلی که در ذهن داشتیم مقدار RPO هدف ۱۰ دقیقه و میزان RTO هدف رو ۲ ساعت در نظر گرفتیم و شروع به طراحی راهحلهامون کردیم.
پیش از شروع توضیح درباره مسیر طراحیمون بهتره که مقداری با طراحی و معماری نسل جدید محصولات همکاران سیستم آشنا بشیم تا در ادامه طراحی نهایی رو در زمینه این معماری ببینیم و ارزیابی کنیم.
معماری نسل چهارم ERP همکاران سیستم
نسل چهارم ERP همکاران سیستم از یک مدل معماری Service Based استفاده میکنه. در این مدل ماژولهای مختلف ERP مثل مالی، فروش، سرمایهانسانی، انبار و… به عنوان پروسههای مجزا مستقر میشن اما، برای حفظ یکپارچگی دادهها در زمان انجام تراکنشهایی که نیاز به ارتباط بین ماژولهای مختلف دارن، به یک پایگاه داده واحد متصل میشن. در ضمن برای پایگاه داده، با توجه به متنباز بودن و جامعه توسعهدهندههای قوی در چند سال اخیر، از PostgreSQL استفاده میکنیم.
برای پیادهسازی این معماری، که به اصطلاح Multi Tenant خونده میشه، در کوبرنیتیز، برای هر مشتری یک نسخه جداگانه از نرمافزار در یک نیماسپیس کوبرنیتیز نصب شده و نرمافزار از طریق وب در اختیار مشتری قرار میگیره. همچنین ابزاری به اسم Tenant Manager بوسیله تیم DevOps توسعه داده شده که با توجه به پیچیدگی مدیریت نرمافزار در یک محیط Multi Tenant، عملیاتهای روز اول مثل نصب و عملیاتهای روز دوم مثل بهروزرسانی، تغییرات پیکربندی و مدیریت پشتیبانگیری پایگاه داده از طریق این ابزار و به صورت خودکار انجام بشه.
روشهای انتخابی برای تهیه پشتیبان
با مراجعه به داکیومنتهای سیستم مدیریت پایگاه داده PostgreSQL برای تهیه پشتیبان از دادهها با سه روش اصلی مواجه میشیم (اینجا رو ببینید):
۱) استفاده از دامپ: به صورت ساده، دامپ در PostgreSQL روشیه که در اون دادههای موجود در پایگاه داده به صورت دستورات SQL استخراج و نگهداری میشن. استفاده از این روش مزیت این رو داره که با توجه به اینکه پشتیبانگیری در لایه SQL انجام میشه، دادههای خروجی قابل انتقال بین نسخههای مختلف PostgreSQL هستن و میشه با توجه به نیازمندی بر اساس ریزدانگیهای مختلف، مثلا یک جدول، دادهها رو بازگردانی کرد. اما در مقابل، این روش یک ضعف قابل توجه هم داره، با شروع عملیات ذخیره دامپ، تمامی دادههای موجود در پایگاه داده به صورت سطر به سطر خونده و ذخیره میشن و برای اطمینان از یکپارچگی دادههای خروجی، باید تمام دادهها به صورتی که در زمان شروع دامپ بودن ذخیره بشن. انجام این عمل بار زیادی رو بر روی پایگاه داده تحمیل میکنه و در محیط عملیاتی باعث کندیهای قابل توجه میشه. علاوه بر این در زمان بازگردانی دادهها، زمان بازگردانی به صورت خطی با حجم داده رشد میکنه و قابل مدیریت نیست.
۲) استفاده از اسنپشات در لایه فایل سیستم: در این روش تمامی دادههایی که سیستم مدیریت پایگاه داده ذخیره کرده به صورت فایل کپی شده و در جای دیگری ذخیره میشن. مزیت این روش سرعت زیاد و راحتی اونه. اما این روش یک عیب بزرگ داره و اون هم اینه که عملیات کپی کردن یک مجموعه از فایلها به صورت اتمی قابل انجام نیست و به همین خاطر برای انجام این کار باید پایگاه داده رو آفلاین کرد تا از این که در زمان عملیات کپی کردن فایلی تغییر نمیکنه اطمینان حاصل بشه. البته که روشهای مختلفی، مبتنی بر فایلسیستمهای خاص برای تهیه اسنپشاتهای اتمی یا کپی کردن دادهها به صورتی که از یکپارچگی اونها مطمئن باشیم وجود داره، اما با توجه به این که ما در محیط پویای کوبرنیتیز بودیم، ریسک استفاده این روشها برای ما قابل پذیرش نبود.
۳) استفاده از PITR: در این روش، ابتدا دادههای فایل سیستم رو کپی کرده و ذخیره میکنیم. بعد از این برای اطمینان از صحت و یکپارچگی دادهها، لاگ تغییرات دادهها که به وسیله سیستم مدیریت پایگاه داده تولید میشه رو هم ذخیره میکنیم و در زمان بازگردانی دادهها از این فایل ذخیره شده، به عنوان یک اسنپشات برای ایجاد یکپارچگی در دادههایی که قبلتر کپی شده بودن استفاده میکنیم. مزیت این روش اینه که نیازی به کپی اتمیک نداریم، سرعت پشتیبانگیری بدون تاثیر بر روی سرعت پایگاه داده حفظ میشه، میشه پشتیبانهای خروجی رو بر اساس تغییراتشون از زمان پشتیبانگیری قبلی ذخیره کرد و مهمتر از همه دادهها رو به یک زمان انتخابی برگردوند. در مقابل ضعف این روش حجم بیشتر اون نسبت به دامپ و پیچیدگی بیشتر پیادهسازی اونه.
همونطور که قبلا در فرضیههامون گفتیم، ما به هیچ یک از سه روشی که توضیح داده شد اعتماد کامل نداشتیم، بنابر این هر سه اونها رو پیادهسازی کردیم. دامپها به صورت دورهای و هر دو ساعت یک بار با اجرای یک جاب کوبرنیتیزی که داخل خودش دستور pg_dump رو اجرا میکنه از دادهها گرفته میشن، کپی فایلسیستم در زمان داونتایم آپدیت نرمافزار و با خاموش کردن سیستم مدیریت پایگاه داده و از طریق VolumeSnapshot در کوبرنیتیز گرفته میشه و در نهایت PITR که در ادامه به جزئیات پیادهسازی اون میپردازیم.
PITR در سیستم مدیریت پایگاه داده PostgreSQL
قبل از اینکه وارد جزئیات پیادهسازی PITR بشیم، بهتره که برای درک اون مقداری با ساختار داخلی پایگاه داده PostgreSQL آشنا بشیم. یکی از تضمینهای مهمی که یک سیستم مدیریت پایگاه داده خوب به ما میده، پایداری یا Durability دادههاست. به طور ساده، این تضمین بیان میکنه که وقتی ما تراکنشی رو ثبت میکنیم و پاسخ پذیرش اون رو از سیستم دریافت میکنیم، تحت هیچ شرایطی داده ما نباید از بین بره. برای پیادهسازی این تضمین میشه در زمان تایید هر تراکنش دادههای اون رو بر روی دیسک نوشت، اما این کار با توجه به اینکه دادهها باید به صورت پیجهای ۸ کیلوبایتی بر روی دیسک نوشته بشن در عمل باعث کند شدن سیستم میشه و به همین خاطر عملی نیست. برای حل این مشکل سیستمهای مدیریت پایگاه داده از روشی به نام لاگ تراکنش (که در PostgreSQL به اون Write Ahead Log یا WAL گفته میشه) استفاده میکنن. در این روش پیجهای اصلی داده در زمان بهروزرسانی فقط در حافظه بهروزرسانی میشن و بعدا در طی عملیات Checkpoint بر روی دیسک نوشته میشن. اما به صورت موازی تمامی تغییراتی که بر روی پایگاه داده صورت میگیره، به صورت یک لاگ سبک و پیوسته بر روی دیسک نوشته میشه تا در صورت رخدادهای ناگهانی، با اجرای دوباره پایگاه داده، تغییرات بر روی پیجها، از آخرین باری که بر روی دیسک نوشته شدن تا لحظه قطعی از لاگ خونده و بر روی پیجها نوشته بشه. با استفاده از این مکانیزم سیستم مدیریت پایگاه داده میتونه تضمین پایداری دادهها رو با یک پرفورمنس مناسب به ما بده.
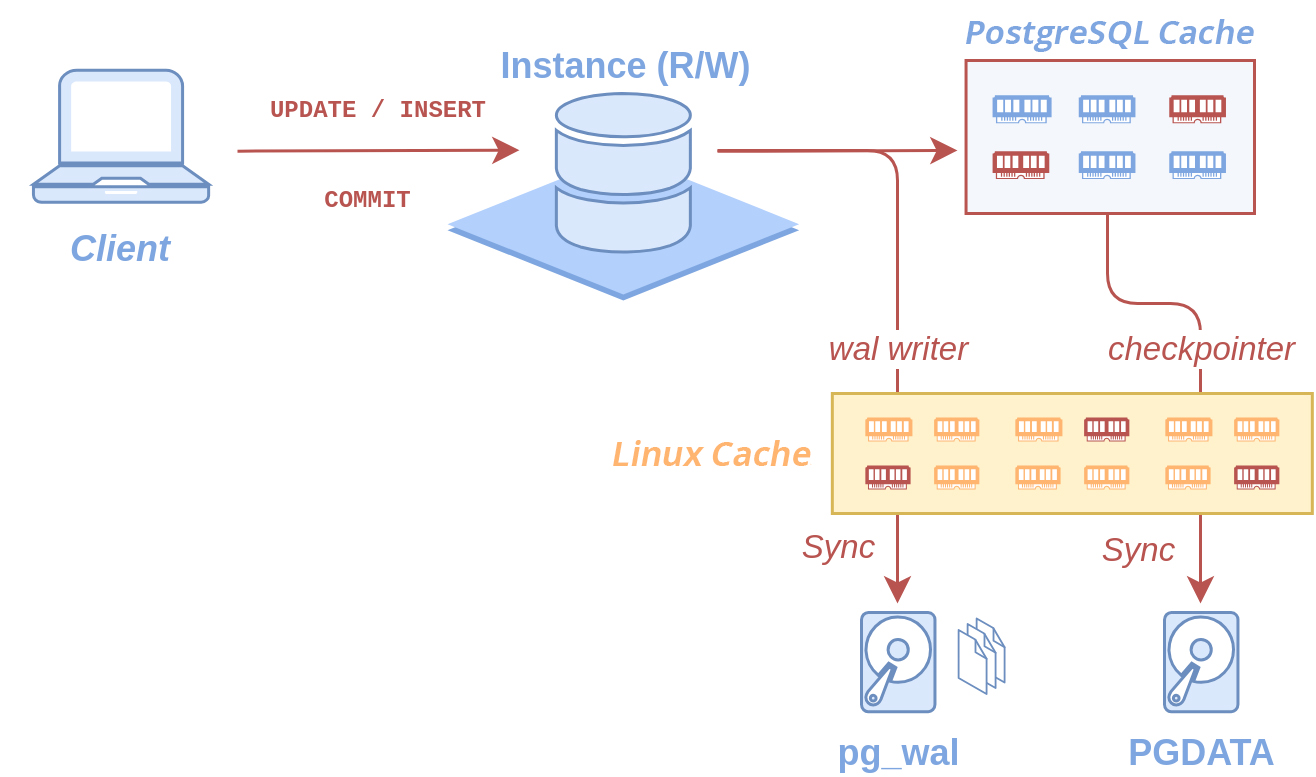
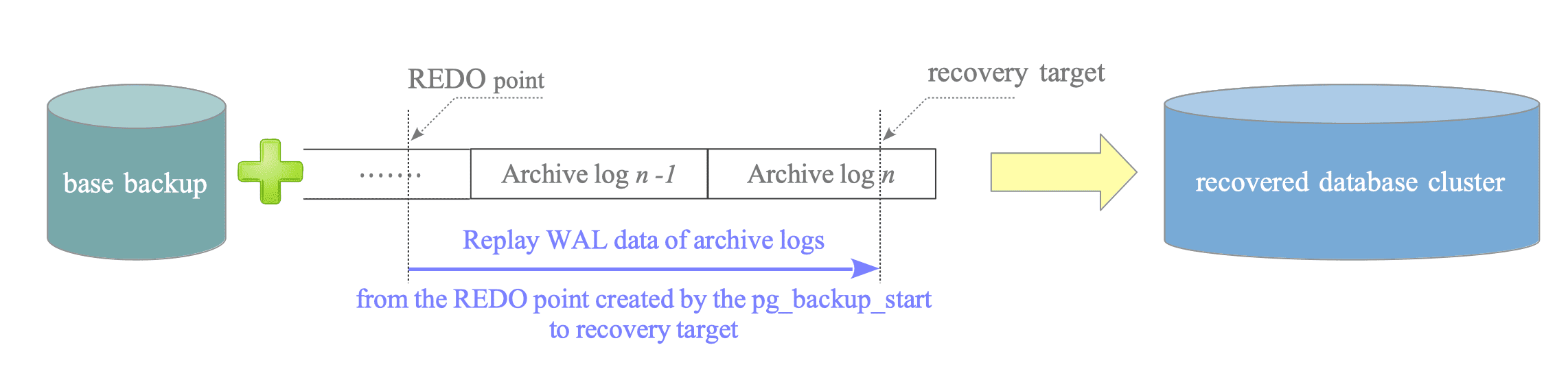
اما این تنها استفاده WAL نیست و با توجه به اینکه تمامی تغییرات پایگاه داده در این لاگ ذخیره میشه، میتونیم از اون به عنوان یک مکانیزم پشتیبانگیری استفاده کنیم. البته که طبیعیه که استفاده از این WALها به تنهایی، به خاطر طولانی شدن زمان بازگردانی پایگاه داده با استفاده از اونها، به صرفه نیست و به همین خاطر نیاز به مکانیزم مکملی وجود داره که به بازگردانی WALها سرعت ببخشه. اسم این مکانیزم Base Backup یا پشتیبان پایهست. این پشتیبان همون پشتیبان در لایه فایل سیستمه، اما با این تفاوت که با توجه به وجود WAL دیگه نیازی به اتمیک بودن نداره چون با بازگردانی این پشتیبان، تمامی تناقضاتی که در زمان کپی در دادهها به وجود اومده با استفاده از خوندن و اجرای WAL قابل حله. در نهایت با استفاده از این دو مکانیزم، یعنی تهیه پشتیبان پایه و ذخیره پیوسته WALها، میتونیم به یک راهحل پایدار برای تهیه پشتیبان از PostgreSQL برسیم. به این صورت که به صورت دورهای پشتیبانهای پایه تهیه و اونهارو ذخیره میکنیم و به صورت موازی با اون، تمامی WALهای مورد نیاز رو هم نگهداری میکنیم. بعد از این و در زمان بازگردانی دادهها، ابتدا پشتیبان پایه رو بازگردانی کرده و با خوندن WALها و اعمال تغییرات اونها بر روی پشتیبان پایه، تا آخرین تراکنش ذخیره شده در WAL رو بازیابی کرده و به وضعیت نهایی پایگاه داده میرسیم.
استفاده از WAL-G برای پیادهسازی PITR
حالا که با کلیات PITR و نحوه کارکرد اون در PostgreSQL آشنا شدیم، خوبه که به چالش اصلی خودمون، یعنی پیادهسازی این مکانیزم در یک محیط ابری Multi Tenant با هدف نگهداری چند ده هزار مشتری، برگردیم. ما برای پیادهسازی این روش در محیط خودمون چندین انتخاب بین ابزارهای موجود داشتیم: WAL-G, pgBackRest, Barman و استفاده از pg_BaseBackup که جزو ابزارهای رسمی PostgreSQL بود اما فقط برای گرفتن پشتیبان پایه بود و راهحلی برای ذخیره WALها ارائه نمیکرد. در نهایت با بررسی و مطالعه این راهحلها، ابزار WAL-G رو به عنوان راهحل پیادهسازی PITR انتخاب کردیم. انتخاب ما چند دلیل داشت: این ابزار بر اساس اصول Cloud native نوشته شده بود و سازگاری خوبی با محیط ما داشت، علاوه بر این امتحانش رو در زیرساختهای بزرگی مثل GitLab و Yandex Cloud که پایگاه دادههای چند ده ترابایتی داشتن پس داده بود و خیالمون رو از بابت پایداری، سرعت و کارکرد صحیح راحت میکرد و در نهایت زبان برنامهنویسی این ابزار بود که Golang بود و با توجه به دانش بالایی که ما به واسطه استک فنی مون از این زبان داشتیم، بهمون این اطمینان رو میداد که در صورتی که با خطایی در این ابزار مواجه بشیم احتمالا میتونیم خودمون اون رو حل کنیم.
برای پیادهسازی مکانیزم پشتیبانگیری با این ابزار باید دو چیز رو داخل زیرساختمون پیادهسازی میکردیم:
۱. ذخیره پیوسته WALها ۲. ذخیره پشتیبانهای پایه
۱) ذخیره پیوسته WALها
سیستم مدیریت پایگاه داده PostgreSQL به صورت پیشفرض لاگهای خودش را در بستههای ۱۶ مگابایتی ذخیره میکنه. وقتی که پایگاه داده در حال کاره با رسیدن حجم تغییرات به ۱۶ مگابایت فایل جدیدی رو ایجاد میکنه و به ما اجازه میده که وقتی که قصد ذخیره WALها رو داریم با تغییر تنظیم archive_mode و فعال کردن اون، با بسته شدن فایل لاگ دستوری که از طریق تنظیم archive_command بهش دادیم رو اجرا کنه تا دستور ما فایل WAL رو کپی کرده و ذخیره کنه. در مورد WAL-G این دستور به صورت زیر اجرا میشه:
wal-g wal-push %pو به WAL-G میگه که فایلی که در مسیر p قرار داره رو در مسیری که در تنظیمات بهش گفتیم، که در مورد ما یک باکت S3 مبتنی بر RGW هستش، ذخیره کنه.
اما اگر تنها وقتی که فایلها به ۱۶ مگابایت میرسن ذخیره بشن، ممکنه که در زمانهایی که پایگاه داده تراکنشهای کمی داره زمان زیادی طول بکشه تا به این حجم برسیم و در صورت خرابی پایگاه داده در طول این مدت، دادههای بیشتری از RPO هدفمون رو از دست بدیم. به همین خاطر با استفاده از یک تنظیم موجود در PostgreSQL به نام archive_timeout که بر اساس مقدار RPOمون تنظیم میشه به سیستم مدیریت پایگاه داده میگیم که با گذشتن این مقدار از زمان، اگر حداقل یک تراکنش رخ داده بود فایل لاگ رو بسته و اون رو برای کپی ارسال کنه تا از رسیدن به RPO مورد نظرمون مطمئن باشیم.
۲) ذخیرهسازی پشتیبانهای پایه
همونطور که قبلا گفتیم، علاوه بر WALها، پشتیبانهای پایه هم باید به صورت دورهای گرفته و ذخیره بشن. برای پیادهسازی این مکانیزم چند راه داشتیم، اجرای WAL-G به صورت دورهای درون کانتینر PostgreSQL و یا به صورت یک Sidecar یا استفاده از جاب کوبرنیتیز. راهحل اول چندین عیب، از جمله عدم توانایی کنترل به صورت ریزدانه بر روی فرآیند تهیه پشتیبان، نیاز به یک پروسه همواره در حال اجرا مثل Crontab برای فراخوانی WAL-G و مصرف دائمی منابعی که با توجه به تعداد بالای مشتریان ما مقدار قابل توجهی میشدند داشت. به همین خاطر به سراغ راهحل دوم یعنی استفاده از جاب کوبرنیتیز رفتیم. در اینجا دوباره دو انتخاب داشتیم، استفاده از پروتکل پشتیبانگیری ریموت، که در WAL-G برای نسخههای جدید PostgreSQL پشتیبانی نمیشد و حتی در صورت امکان هزینه بالایی رو از نظر بار بر روی شبکه به ما تحمیل میکرد و اتصال مستقیم به PVC پوستگرس. برای اتصال مستقیم به PVC پوستگرس، با توجه به اینکه PVهای مبتنی بر Block Storage بر روی چندین نود قابل ماونت نیستند، از یک Affinity بین پاد PostgreSQL و جاب پشتیبانگیری استفاده کردیم تا مطمئن باشیم که پاد جاب پشتیبانگیری بر روی نود یکسانی قرار میگیره. در نهایت و درون این جاب با استفاده از دستور:
wal-g backup-push -f $PGDATAاز فایلهای پایگاه داده پشتیبان تهیه کرده و در S3 ذخیره میکنیم.
با پیادهسازی این دو مکانیزم، مسیر پشتیبانگیری تکمیل شده بود و باید به سراغ ایجاد راهی برای بازگردانی دادهها در زمان بحران میرفتیم. که در ادامه به پیادهسازی روش مورد استفاده برای این کار میپردازیم.
بازگردانی دادهها
مسیر ما برای بازگردانی دادهها، با توجه به اینکه این کار بر خلاف پشتیبانگیری که به صورت خودکار انجام میشد، باید به صورت آگاهانه و به وسیله مدیر سیستم انجام بشه، کمی متفاوت بود. به خاطر نیازمندی کنترل دقیقی که بر روی این فرآیند وجود داشت، تصمیم گرفتیم که اون رو در داخل Tenant Manager پیادهسازی کنیم تا در عین راحتی کاربرهای سیستم، بتونیم هر بازگردانی داده رو به صورت دقیق کنترل و Audit کنیم. بازگردانی در این محیط دو بخش داره، بخش اول کارهاییه که باید درون پاد PostgreSQL انجام بشه و بخش دوم کارهاییه که باید بوسیله Tenant Manager و در ارتباط با کوبرنیتیز پیش بره.
بازگردانی PITR در PostgreSQL
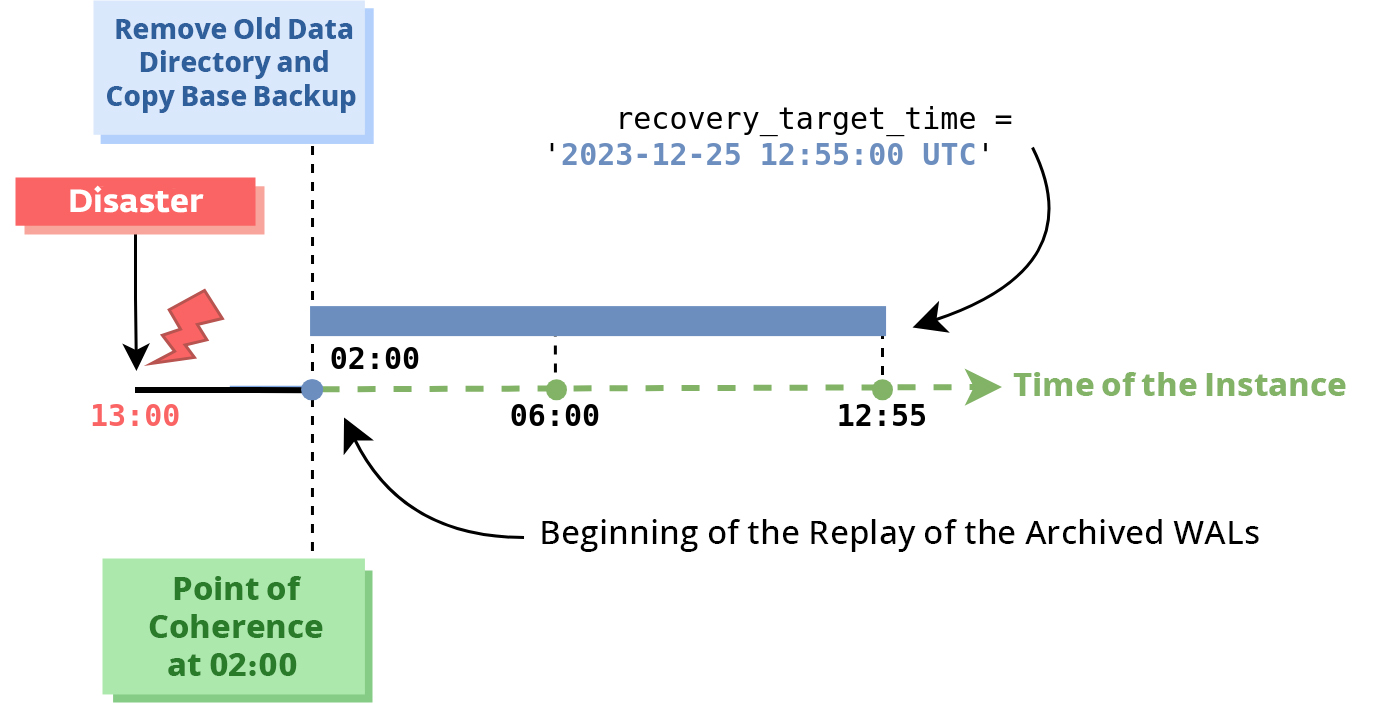
برای بازگردانی دادهها از طریق فرآیند PITR در پایگاه داده PostgreSQL ابتدا باید پایگاه داده مورد نظر رو خاموش کنیم و دادههای فعلی اون رو پاک کنیم. بعد از اون باید جدیدترین پشتیبان پایه قبل از زمان مقصدمون (که میتونه زمانی در گذشته یا زمان آخرین تراکنش باشه) رو دریافت کرده و در مسیر دادهها قبلی قرار بدیم. این کار با اجرای دستور:
wal-g backup-fetch "${DATA_DIR}" "${BASE_BACKUP_NAME}"انجام میشه که در اون DATA_DIR آدرس دایرکتوری فایلهای پایگاه داده و BASE_BACKUP_NAME نام پشتیبان پایه انتخاب شده هستن. بعد از قرارگیری دادههای پشتیبان پایه در مسیر فایلهای پایگاه داده، با اضافه کردن تنظیمات مختص به بازگردانی یعنی Recovery_Target_Action که برای بازگردانی پایگاه داده اصلی بر روی Promote تنظیم میشه، Recovery_Target_Time که در صورت نیاز به بازگردانی دادهها به زمانی پیش از زمان آخرین تراکنش و بر روی زمان مقصد مورد نظرمون تنظیم میشه و در نهایت Restore_Command که با استفاده از اون به پایگاه داده میگیم که برای دریافت WALها چطور با WAL-G در ارتباط باشه. این دستور در زیرساخت ما به این صورت تنظیم شده:
wal-g wal-fetch %f %pکه f نام فایل WAL مورد نظر پایگاه داده و p مقصدی که اون فایل باید درش قرار بگیره رو مشخص میکنه.
با تنظیم کردن پایگاه داده برای بازگردانی یک فایل با نام Recovery.Signal در دایرکتوری دادهها ایجاد میکنیم تا سیستم مدیریت پایگاه داده با دیدن این فایل متوجه قصد ما برای بازگردانی دادهها بشه و عملیات رو ایجاد کنه و در نهایت و پس از انجام این کارها، سیستم مدیریت پایگاه داده رو دوباره روشن میکنیم. با روشن شدن PostgreSQL، این سیستم مدیریت پایگاه داده به طور خودکار متوجه اینکه در حالت بازگردانی قرار گرفته میشه و درخواست دانلود WALهایی که برای اجرا بر روی پشتیبان پایه نیازه رو به ترتیب برای WAL-G ارسال و پس از دریافتشون تمام تغییرات ثبت شده در اونهارو اجرا میکنه تا در نهایت به زمان مقصد مورد نظر ما که پیشتر تنظیم شده بود برسه.
صحتسنجی سلامت دادهها
طبیعتاً دادههای پشتیبان تنها تا زمانی با ارزشن که قابل بازگردانی باشن. به همین خاطر مهمترین چالش ما بعد از پیادهسازی فرآیندهای پشتیبانگیری و بازگردانی، اطمینان از سلامت دادههای پشتیبانگیری شده بود. ما برای رسیدن به این هدف باز از چند مسیر مختلف پیش رفتیم تا از صحت سلامت دادهها مطمئن باشیم. ما میدونستیم که مسیر مطمئن شدن از صحت فایلهای پشتیبان احتمالا نیاز به انجام کارهای مختلف و پرهزینه داشته باشه، برای همین ابتدا سعی کردیم که با انجام یک کار کم هزینهتر به صورت مداوم از صحت حدودی سیستمی که داشتیم اطمینان حاصل کنیم و در کنار اون با انجام دورهای کار پرهزینهتر، اطمینانمون از صحت رو بیشتر کنیم.
استفاده از دستور WAL-G WAL Verify
ابزار WAL-G برای اطمینان از رسیدن صحیح فایلهای WAL به زیرساخت ذخیرهسازی دستوری به نام Wal-Verify ارائه میده. این دستور ابتدا به سیستم مدیریت پایگاه داده متصل میشه و نام سگمنت WAL فعلی رو از این سیستم دریافت میکنه. بعد از اون، با اتصال به S3 و گرفتن لیست فایلهای WAL از اون، چک میکنه که تمامی فایلها به درستی به S3 منتقل شده باشن. در زیرساخت ما، این دستور به صورت دورهای ولی با فرکانس بالا برای پایگاه دادههای تمامی مشتریان اجرا میشه و در صورتی که فایلی در S3 موجود نباشه، برای مدیران سیستم هشداری ارسال میکنه تا وضعیت رو بررسی و در صورت نیاز مداخله کنند.
صحتسنجی فرآیند PITR از طریق Tenant Manager
بعد از پیادهسازی Wal-Verify و پس از مدتی تحقیق، به این نتیجه رسیدیم که تنها راه کاملا مطمئن برای اطمینان از صحت دادههای پشتیبان گیری شده، بازگردانی و چک کردن اونها در یک محیط آزمایشیه. برای رسیدن به این هدف، نیاز بود که مثل فرآیند بازگردانی داده، از Tenant Manager کمک بگیریم. برای این کار به موجودیت تننت ویژگیای اضافه کردیم که مشخص میکرد آخرین باری که پشتیبانهای اون صحتسنجی شدن چه زمانی بودن. بعد از اون زیرساختی رو پیاده سازی کردیم که به صورت دورهای و بر اساس اولویت و آخرین زمان صحتسنجی، گروهی از تننتها انتخاب و عملیات صحتسنجی بر روی اونها اجرا میشد. مسیر عملیات صحتسنجی به این شکل هستش که بر روی یک نیماسپیس مجزای کوبرنیتیز سیستم مدیریت پایگاه داده اجرا میشه و عملیات بازگردانی دادههای پشتیبان تننت، دقیقا به همون شکل اصلی و به صورت کامل، بر روی اون انجام میشه. در نهایت و بعد از اتمام بازگردانی، با اجرای یک جاب تعدادی کوئری مختلف به سمت پایگاه داده ارسال میشه تا از صحت و بهروز بودن دادهها اطمینان حاصل بشه. چنانچه در طول این مسیر هر یک از مراحل با خطا مواجه بشه، با ارسال یک هشدار مدیران سیستم با خبر میشن تا در فرآیند مداخله کرده و هرچه زودتر یک پشتیبان پایه جدید ایجاد کرده و برای حل مشکل پشتیبان پایه قدیمی تلاش کنند.
چالشهای ما در مسیر پیادهسازی PITR
مسیری که تا اینجای کار دوره کردیم، برای درک بهتر و خطی بودن، برخی از چالشهایی که با اونها برخورد کردیم رو نادیده گرفته بود. اما مثل هر چیز دیگری، در واقعیت درگیریها، چالشها و ریسکهای مختلفی رو تجربه کردیم که در ادامه به برخی از اونها و راهحلهایی که برای حلشون پیدا کردیم میپردازیم.
پاک شدن دادههای پشتیبان به خاطر از بین رفتن PV درون کوبرنیتیز
در یکی از حوادثی که در زیرساخت ما رخ داد، به اشتباه PV یکی از پایگاههای داده پاک شد، با ساخت PV این پایگاه داده و اجرای دوباره اون، فرآیند بازگردانی دامپ رو برای بازگشت دادهها شروع کردیم اما در میانه مسیر متوجه شدیم که شماره فایلهای WAL دوباره از ۱ شروع شده و WAL-G در حال جایگزین کردن فایلهاییه که قبلا آپلود کرده بود. با توجه به اینکه این مسئله به معنای از دست رفتن بخشی از دادههای پشتیبان بود و اکیدا برای ما قابل پذیرش نبود، شروع به بررسی این مسئله کردیم. با بررسی بیشتر این مسئله متوجه شدیم که زمانی که سیستم مدیریت پایگاه داده PostgreSQL دوباره اجرا شده به خاطر نداشتن دادهای از قبل از صفر شروع به کار کرده و به همین خاطر شروع به ساخت فایلهای WAL با آیدی ۱ کرده. برای حل این مسئله و جلوگیری از تکرار دوباره اون نیاز به خصوصیتی داشتیم که اجازه بده بین پایگاههای دادهای که در چنین مواردی تغییر میکردن تمایز قائل بشیم. با کمی جستوجو و بررسی منابع مختلفی مثل داکها و کدهای ابزارهای مختلفی که برای مدیریت پایگاه داده PostgreSQL وجود داشت، و به طور خاص کنترلرهایی که برای مدیریت این سیستم مدیریت پایگاه داده در کوبرنیتیز وجود داره، فهمیدیم که خوشبختانه خود PostgreSQL چنین چیزی رو به ما میده.
هر کلاستر پایگاه داده PostgreSQL در زمان شروع به کارش و بر اساس زمان یک آیدی ۶۴ بیتی به نامDatabase System Identifier ایجاد میکنه که به احتمال زیاد یکتاست. اضافه کردن این آیدی به عنوان یک متادیتا در کنار پشتیبانها به ما اجازه میداد که در صورت ریست شدن پایگاه داده و شروع به کار دوباره، پشتیبانهای جدید رو با توجه به System Identifier جدید ذخیره کنیم تا دادههای پشتیبانی که از پایگاه داده با System Identifier قبلی وجود دارن جایگزین نشن. البته در کنار این و برای اطمینان بیشتر و جلوگیری از مشکلات آینده، دو کار دیگه رو هم انجام دادیم. اولی اضافه کردن نسخه پایگاه دادهای که این پشتیبان ازش گرفته شده بود در کنار System identifier بود تا مطمئن باشیم که با توجه به ناسازگاری پشتیبانهای نسخههای مختلف پایگاه داده به اشتباه پشتیبان یک نسخه رو بر روی نسخه دیگهای بازگردانی نکنیم و همینطور استفاده از متغیر محیطی WALG_PREVENT_WAL_OVERWRITE بود که با ست شدنش به جای جایگزین کردن فایلهای WAL موجود فرآیند ارسال رو با ارور متوقف میکنه.
باگهای WAL-G در مسیر پشتیبانگیری از پایگاه دادههای بزرگ
همونطور که پیشتر گفتیم، تمام طراحیهای ما باید کلاسترهای کوبرنیتیزی با چند صد تا چند هزار مشتری رو پشتیبانی میکردن. به همین خاطر و با مشاهده دادههایی که از بار ایجاد شده بر روی کلاستر در زمان پشتیبانگیری داشتیم، تصمیم گرفتیم که زمان پشتیبانگیری از دادهها رو کاهش بدیم و شروع به تحقیق در رابطه با این مسئله و انتخابهایی که داشتیم کردیم.
پیش از توضیح مشکلی که در ادامه برامون ایجاد شد، ابتدا باید با چند تا از تنظیمات WAL-G که در کنار هم باعث این مشکل میشدن آشنا بشیم.
اگر به داکیومنت تنظیمات WAL-G مراجعه کنیم، میبینیم که برای ایجاد یک پشتیبان پایه از چند حالت مختلف پشتیبانی میکنه. در حالت اصلی و ساده، این ابزار تمامی فایلهای موجود در دایرکتوری سیستم مدیریت پایگاه داده رو بررسی کرده و اونهارو در چند بخش و به صورت فایلهای با فرمت tar در S3 ذخیره میکنه. این راه با وجود ساده بودن، برای همه سناریوها بهینه نیست و به همین خاطر راههای دیگری برای ذخیره پشتیبان وجود داره. یکی از این راهها که برای کاهش مدت زمان پشتیبانگیری برای ما جذاب بود، Copy Composer بود. در این روش ابزار WAL-G با بررسی فایلهای موجود و مقایسه اونها با فایلهای موجود در پشتیبان پایه قبلی، اگر بسته tar قدیمیای پیدا کنه که هیچکدوم از فایلهای اون تغییر نکردن، همون فایل رو برای پشتیبان پایه جدید کپی میکنه. این روش به ما اجازه میده که بتونیم با داشتن یک پشتیبان پایه کامل و حفظ RTO، سرعت پشتیبانگیری رو هم افزایش بدیم.
یکی دیگه از تنظیماتی که WAL-G به ما ارائه میده، WALG_UPLOAD_DISK_CONCURRENCY هستش. این تنظیم مشخص میکنه که در زمان اجرای فرآیند پشتیبانگیری به صورت موازی چند فایل خونده میشن و به صورت پیشفرض بر روی ۱ ست شده.
بعد از تحقیق و بررسی WAL-G و با توجه به هدفی که برای کاهش زمان پشتیبانگیری داشتیم، تصمیم گرفتیم که مقدار WALG_UPLOAD_DISK_CONCURRENCY رو افزایش بدیم و در موارد خاص از Copy composer استفاده کنیم اما با فعالسازی این دو تنظیم با هم و اجرای فرآیند پشتیبانگیری مشاهده کردیم که در پایان عملیات ابزار WAL-G پنیک کرده و ارورهای زیر رو خروجی میده:
ERROR: 2025/07/14 03:17:52.341532 archive/tar: missed writing 8192 bytes
PackFileTo: failed to write header
github.com/wal-g/wal-g/internal.PackFileTo
/home/runner/work/wal-g/wal-g/internal/tar_ball.go:26
github.com/wal-g/wal-g/internal/databases/postgres.(*TarBallFilePackerImpl).PackFileIntoTar.func2
/home/runner/work/wal-g/wal-g/internal/databases/postgres/tar_ball_file_packer.go:111
golang.org/x/sync/errgroup.(*Group).Go.func1
/home/runner/work/wal-g/wal-g/vendor/golang.org/x/sync/errgroup/errgroup.go:75
runtime.goexit
/opt/hostedtoolcache/go/1.20.14/x64/src/runtime/asm_amd64.s:1598
PackFileIntoTar: operation failed
github.com/wal-g/wal-g/internal/databases/postgres.(*TarBallFilePackerImpl).PackFileIntoTar.func2
/home/runner/work/wal-g/wal-g/internal/databases/postgres/tar_ball_file_packer.go:113
golang.org/x/sync/errgroup.(*Group).Go.func1
/home/runner/work/wal-g/wal-g/vendor/golang.org/x/sync/errgroup/errgroup.go:75
runtime.goexit
/opt/hostedtoolcache/go/1.20.14/x64/src/runtime/asm_amd64.s:1598در ابتدا مشخص نبود که این ارور چرا رخ میده به همین خاطر با توسعهدهندههای WAL-G مرتبط شدیم و درباره این مشکل پرس و جو کردیم و در نهایت در صحبت با اونها متوجه شدیم که این مسئله نه از روی طراحی و بلکه یک باگه و به همین خاطر شروع به بررسی و دیباگ کردن کد WAL-G شدیم. با بررسیهای بیشتر متوجه شدیم که این باگ به خاطر استفاده همزمان از یک متغیر لوکال در چند گو روتین که وظیفه آپلود فایلها رو بر عهده داشتن رخ میده و با حل اون پول ریکوئستش رو برای WAL-G ارسال کرده و با کمک توسعهدهندههای این ابزار با کدبیس اصلی مرجش کردیم. (https://github.com/wal-g/wal-g/pull/2020)
مسیر آینده
پشتیبانی از بازگشت به خط زمانهای مختلف در Tenant Manager
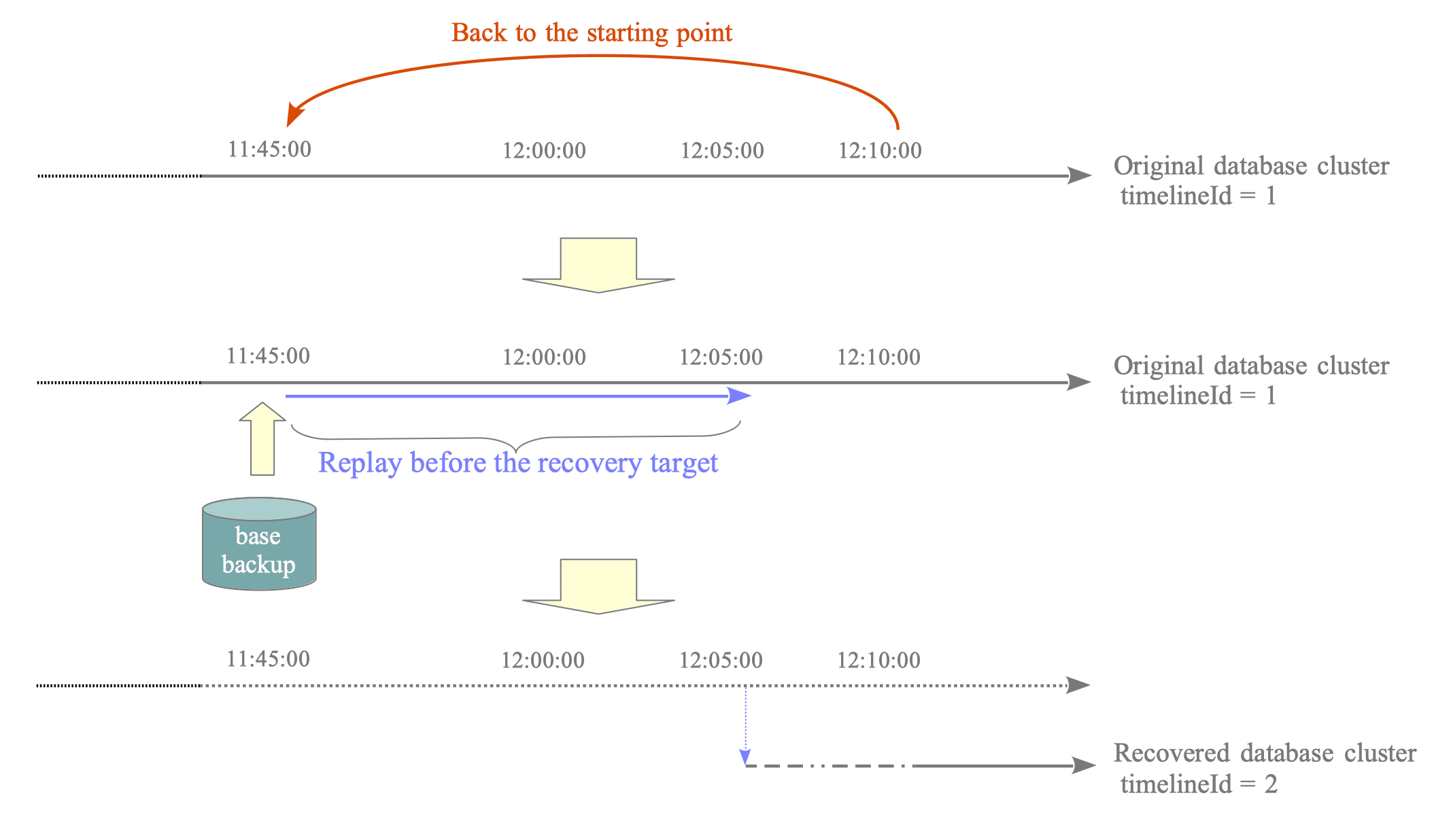
یکی از مسائل دیگری که در پیادهسازی PITR در پایگاه داده PostgreSQL با اون برخورد میکنیم، مسئله تایملاینها یا خط زمانها است. زمانی که یک پایگاه داده رو به یک نقطه از گذشته بازگردانی میکنیم، پایگاه دادهای که از اون نقطه از زمان شروع به کار کرده باید WALهای جدیدی از نقطهای در زمان که در این بازگردانی از اونجا شروع به کار کرده تولید کنه. با توجه به اینکه این WALهای جدید باید با همون شمارههایی که در گذشته تولید شده بودن تولید بشن اما WALهای قدیمی رو جایگزین نکنن، سیستم مدیریت پایگاه داده مفهومی به نام خط زمان داره که پس از هر بازگشت تغییر میکنه تا همزمان با نگهداری WALهای قدیمی بتونه WALهای جدید رو هم مدیریت کنه. برای درک بهتر این مفهوم بهتره که با یک مثال بیشتر بررسیش کنیم. تصور کنید که در روز سهشنبه ساعت ۱۵:۰۰ در حال کار با پایگاه داده هستید و تغییری در دادهها ایجاد میکنید. پس از ایجاد تغییر متوجه یک اشتباه میشید و پایگاه داده رو به ساعت ۱۴:۵۵ دقیقه بازگردانی میکنید. حالا تصور کنید که بعد از بازگردانی بفهمید که موازی با تغییرات شما تغییرات دیگهای هم در جریان بوده که ارزش بیشتری داشته و این بازگردانی، اون تغییرات رو از بین برده. در چنین مواقعی قابلیت خط زمان به شما اجازه میده که پایگاه داده رو به خط زمان قبلی که تا ساعت ۱۵:۰۰ ادامه داشته بازگردانی کنید و دادههای مهمی که حذف شدن رو کپی کنید.
در حال حاضر ما با توجه به مفروضاتی که از نیازمندیهامون داشتیم، قابلیت بازگشت به خطوط زمان رو در Tenant Manager پیادهسازی نکردیم و با بازگشت به یک نقطه از زمان، فرض میکنیم که بازگشت به نقطهای بعد از اون زمان غیر ممکنه اما دادههای مورد نیاز رو به صورت کامل نگهداری میکنیم. با توجه به اینکه چنین سناریوهایی کمتر پیش مییان اما در صورت بوجود اومدنشون احتمالا خیلی مهم هستن، در مسیر آیندمون پیادهسازی پشتیبانی از این قابلیت در Tenant Manager رو در نظر داریم.
استفاده از پشتیبانگیری Incremental برای افزایش کارایی سیستم و کاهش RTO
در دنیای نگهداری پشتیبانها همواره بین زمان مورد نیاز برای پشتیبانگیری، زمان مورد نیاز برای بازگردانی اون داده پشتیبان و میزان فضای ذخیرهسازی استفاده شده یک بده بستان وجود داره. با افزایش فاصله بین پشتیبانهای پایه زمان مورد نیاز برای بازگردانی اونها هم با توجه به نیاز به بازاجرای تعداد بیشتری فایل WAL، بیشتر میشه. یک راه برای مقابله با این مشکل، افزایش فرکانس پشتیبانگیریها و استفاده از قابلیت Copy Composer ابزار WAL-G هستش که با هزینه کردن فضای ذخیرهسازی زمان پشتیبانگیری و زمان بازگردانی رو کاهش میده. اما راه دیگهای هم وجود داره که در این بده بستان در نقطه دیگهای قرار میگیره و سعی میکنه تعادل عادلانهتری بین این سه مسئله برقرار کنه. پشتیبانگیری Incremental یا افزایشی با بررسی فایلهایی که از آخرین پشتیبانگیری تغییر نکردن، صرفا اشارهگری به پشتیبان قبلی نگه میداره و تنها فایلهایی که تغییر کردن رو کپی میکنه. با انجام این کار ما میتونیم با افزایش فرکانس پشتیبانگیری و بدون پرداخت هزینه زیاد برای فضای ذخیرهسازی هم سریع پشتیبانگیری کنیم و هم سریع پشتیبانهارو بازگردانی کنیم. البته باید به این نکته توجه کرد که زمان مورد نیاز برای بازگردانی دادههای پشتیبان Incremental با توجه به سرباری که برای ترکیب اونها و ساخت یک پشتیبانکامل وجود داره، نسبت به یک داده پشتیبان کامل بیشتره اما با توجه به نیازمندی به بازاجرای تعداد کمتری از فایلهای WAL، این سربار از یک نقطه به بعد قابل چشمپوشی میشه. در زیرساخت ما، با توجه به استفاده از قابلیت Copy Composer، تا این لحظه به سراغ استفاده از بکاپهای Incremental در محیط اصلی نرفتیم اما با توجه به دادههایی که از رشد حجم پایگاههای داده و نیازمندیهای دیگهای که در این زمینه پیشبینی میکنیم داریم، احتمالا در آیندهای نزدیک به پیادهسازی کامل این قابلیت خواهیم پرداخت.
جمعبندی
مسیری که با هم مرور کردیم، مسیر پر پیچ و خم پیادهسازی پشتیبانگیری در زیرساخت ما بود. دیدیم که چطور میشه با استفاده از ابزار WAL-G از دادههای یک پایگاه داده PostgreSQL پشتیبان تهیه کرد و چطور پشتیبانهای تهیه شده رو بازگردانی کرد. همچنین به روشهای مختلفی که برای اطمینان از سلامت دادههای پشتیبان وجود داره پرداختیم و در نهایت با چالشهایی که داشتیم و راهی که برای آینده در نظر داریم آشنا شدیم. همونطور که قبلاً هم اشاره کردیم این راه برای ما تموم نشده و میدونیم که هنوز نیاز به بهبود پیوسته اون داریم اما با توجه به اینکه تا الان در یک زیرساخت نسبتا بزرگ آزموده شده، تصمیم گرفتیم که تجربیاتی که تا به اینجای کار کسب کردیم رو با شما به اشتراک بگذاریم و امیدوار باشیم که این تجربیات بتونه به درد کسانی که سعی دارن این مسیر رو طی کنند بخوره. ما در کنار فرآیندهایی که برای پشتیبان گیری پیادهسازی کردیم، فرآیندهای مختلف دیگری هم برای بررسی و اطمینان از صحت کارکرد پایگاه داده و بهروز رسانی اون و به طور کلیتر فرآیندهایی برای مدیریت زیرساخت داریم که به طور عمده در Tenant Manager پیادهسازی شدهاند و امیدواریم که بتونیم در آیندهای نه چندان دور تجربیاتمون رو در اون زمینهها با شما به اشتراک بگذاریم تا هم سهم خودمون رو در افزایش دانش ادا کرده باشیم و هم بتونیم از طریق بازخوردها و نظراتی که دریافت میکنیم کارمون رو بهبود بدیم.
از طرف خودم و فرزاد خدارحیمی، هادی جعفری و مهدی قلعهنویی که در مسیر پیادهسازی قابلیتهای پشتیبانگیری درگیر بودن از شما تشکر میکنیم.
مطلبی دیگر از این انتشارات
مدیریت حافظه در Go
مطلبی دیگر از این انتشارات
روایتهایی از تجربه، یادگیری و رشد در تیم تولید همکاران سیستم
افزایش بازدید بر اساس علاقهمندیهای شما
۷ معیار طلایی برای انتخاب شرکت پشتیبانی شبکه؛ قبل از عقد قرارداد بخوانید